Atomic Habits: a personal summary
Here is my summary of Atomic Habits based on each chapter, and I hope this information can give you an idea of what the book is about, so you can read it yourself and get all of the benefits.

Event Sourcing and CQRS are design patterns that are great for some domains. The Incident library will help implement them without compromising other parts of your application.

This is the first of a series of posts that I will present on how your application can use Event Sourcing and CQRS for specific domains with an open-source library that I am developing called Incident.
UPDATE: this post is updated with Incident latest version 0.6.0, including its configuration.
My first contact with Event Sourcing was back in 2016 when I was working for Raise Marketplace and I led a project that the goal was to solve an accounting burden regarding seller payments. As a marketplace, in a nutshell, a buyer pays for something, the company gets a commission and the seller receives the remaining funds. Track the money flow, depending on the options the marketplace offers, can become complex. In that specific case, sellers could opt for combining funds to be paid daily, via different methods such as check, PayPal, ACH, and so on, or decide to request funds one by one. Around all of that, there was a fraud detection process, transfer limits, a different category of sellers, and so on.
Before Event Sourcing, there was a lack of a cohesive way to track the steps of each fund, from buyer to seller, and all possible scenarios. And when that comes to accounting people, it becomes a nightmare.
With well-defined commands, events, and logic associated with them, it became more clear the information the Accounting department needed at the time.
Later on, I had the opportunity to work on other personal projects using Event Sourcing so I decided to build something to help me moving forward, and from that learning came Incident.
Event Sourcing is a design pattern that defines that the state changes of an entity are stored as a sequence of events. Events are the source of truth and immutable, and the current state of any entity is playing all events of the entity in the order they happened.
If you are new to Event Sourcing and CQRS I highly recommend watch Greg Young's presentation at Code on the Beach 2014 before moving forward as my intention with this blog post series is not to present Event Sourcing principles per se and the details but how those principles were used in the implementation.
One of the misconceptions that I often see is that if you decide to use Event Sourcing you should apply it to your entire system, to all your domains. This is wrong in my opinion, an anti-pattern and you should avoid at all costs as unlikely all your domains will suit.
Another fact, Event Sourcing is not new, many industries using "Event Sourcing" concepts even not naming the same way. Accounting keeps track of all account operations, your medical record is about your health history, contracts don't change, they have addendums, and so on.
When I decided to implement a new library, based on my learning through other projects, I had some goals in mind that I'd like to achieve:
Events are the source of truth in any Event Sourcing domain, they are immutable and they are used to calculate the current state of any aggregate (or entity) at any time. All the events of any type, for any aggregate type, are stored in the Event Store in a single table.
The projections are the representation of the current state of an aggregate and they are very similar to what any system that does not use Event Sourcing has. The domain will have as many projection tables as you need but usually, you will have one table for each entity type. All projection tables are stored in the Projection Store.
The following diagram helps understand the separation between the command model from the query model, and their responsibilities as well.
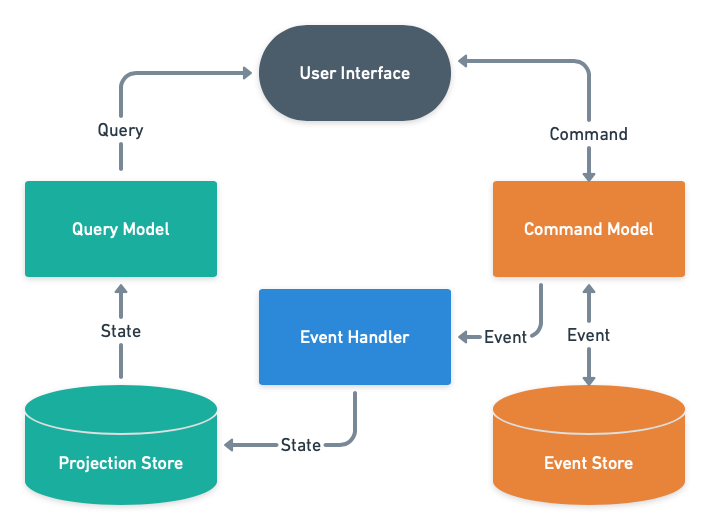
One of the things that I see when implementing Event Sourcing that makes it harder is to try to manage aggregate logic, aggregate state data structure, and aggregate state logic in the same place. Incident does a little differently.
The Aggregate will define how a specific entity (Bank Account, for example) will execute each of its allowed commands and apply each of its allowed events. The aggregate itself only defines the logic but not the current state calculation.
The Aggregate State defines the initial state of an Aggregate and it is able to calculate the current state by replaying all the events through the aggregate logic.
Back in 2013, Greg Young tweeted the following:
want to learn event sourcing?
— Greg Young (@gregyoung) March 17, 2013
f(state, event) => state
Incident follows that principle with the Aggregate logic in a nutshell being:
And part of the Aggregate State logic is similar to:
Enum.reduce(events, state, fn event, state ->
aggregate.apply(event, state)
end)
In this series we will be using Incident to implement the Account domain of a Bank system for these main reasons:
Other common domains of a typical Bank system, for example, Client Profile, Authentication/Authorization won't be the focus of the Incident implementation as they are not a good fit, at least not in our case. This is to emphasize the fact that you don't need to have Event Sourcing in your entire system.
Let's create a new application for our Bank, including the supervision tree. As a side note, I am using Elixir 1.11 in this series so some of the Elixir configuration details might vary depending on the version you are using.
~> mix new bank --sup
Add Incident in mix.exs, fetch and compile the dependencies:
defmodule Bank.MixProject do
use Mix.Project
# hidden code
def deps do
[
{:incident, "~> 0.6.0"}
]
end
end
~> mix do deps.get, deps.compile
Generate Ecto Repos for the Event Store and Projection Store, this will create the repo modules:
~> mix ecto.gen.repo -r Bank.EventStoreRepo
...
~> mix ecto.gen.repo -r Bank.ProjectionStoreRepo
...
In your application config/config.exs specify the Ecto repos:
config :bank, ecto_repos: [Bank.EventStoreRepo, Bank.ProjectionStoreRepo]
import_config "#{config_env()}.exs"
In your application config/dev|test|prod.exs (the example below defines two separated databases but it could be the same one), set up the database access for Ecto for each environment:
# config/dev.exs
# hidden code
config :bank, Bank.EventStoreRepo,
username: "postgres",
password: "postgres",
hostname: "localhost",
database: "bank_event_store_dev"
config :bank, Bank.ProjectionStoreRepo,
username: "postgres",
password: "postgres",
hostname: "localhost",
database: "bank_projection_store_dev"
Incident will be started under your supervisiont tree with proper configuration based on the adapter you are using. Also, add the Ecto repo modules in your lib/bank/application.ex:
defmodule Bank.Application do
@moduledoc false
use Application
@impl true
def start(_type, _args) do
config = %{
event_store: %{
adapter: :postgres,
options: [repo: Bank.EventStoreRepo]
},
projection_store: %{
adapter: :postgres,
options: [repo: Bank.ProjectionStoreRepo]
}
}
children = [
Bank.EventStoreRepo,
Bank.ProjectionStoreRepo,
{Incident, config}
]
opts = [strategy: :one_for_one, name: Bank.Supervisor]
Supervisor.start_link(children, opts)
end
end
Create the database(s), generate the Incident events table migration, and run the migrations:
~> mix ecto.create
...
~> mix incident.postgres.init -r Bank.EventStoreRepo
...
~> mix ecto.migrate
...
The setup is done, it seems a lot but most of it is a common setup needed for any application using Ecto.
As we will keep track of bank accounts, we will define some initial components that are defined only once, and then later evolve the aggregate with the logic that will be based on the operations we want the aggregate to respond to.
We will need to present to the user some bank account information. So we will define one projection that will contain the current state of the bank accounts. Generate an Ecto migration as below, please notice the -r flag that specifies which repo the migration will be:
~> mix ecto.gen.migration CreateBankAccountsTable -r Bank.ProjectionStoreRepo
Populate the migration with the following fields. Besides the desired fields related to bank account data, every projection should also contain version, event_id, and event_date fields. They inform the last event that updated the projection and how many events were applied to it:
defmodule Bank.ProjectionStoreRepo.Migrations.CreateBankAccountsTable do
use Ecto.Migration
def change do
create table(:bank_accounts) do
add(:aggregate_id, :string, null: false)
add(:account_number, :string, null: false)
add(:balance, :integer, null: false)
add(:version, :integer, null: false)
add(:event_id, :binary_id, null: false)
add(:event_date, :utc_datetime_usec, null: false)
timestamps(type: :utc_datetime_usec)
end
create(index(:bank_accounts, [:aggregate_id]))
end
end
And the bank account projection schema:
defmodule Bank.Projections.BankAccount do
use Ecto.Schema
import Ecto.Changeset
schema "bank_accounts" do
field(:aggregate_id, :string)
field(:account_number, :string)
field(:balance, :integer)
field(:version, :integer)
field(:event_id, :binary_id)
field(:event_date, :utc_datetime_usec)
timestamps(type: :utc_datetime_usec)
end
@required_fields ~w(aggregate_id account_number balance version event_id event_date)a
def changeset(struct, params \\ %{}) do
struct
|> cast(params, @required_fields)
|> validate_required(@required_fields)
end
end
The first operation we will allow is the ability to open a bank account. One of the advantages of Event Sourcing is called ubiquitous language. Every operation in the application is called by what normally the business understands it. Instead of creating a bank account, that is very database-driven, a bank account would be opened. This same language guides us on how we name commands (intentions) and events (facts), there is no need for business > technical, or vice-versa, translations.
Let's define an Open Account command. Commands in Incident define the command data and also can validate themselves. You can use Elixir structs or Ecto Schemas with Changesets, as long as it implements valid?/1.
defmodule Bank.Commands.OpenAccount do
@behaviour Incident.Command
use Ecto.Schema
import Ecto.Changeset
@primary_key false
embedded_schema do
field(:aggregate_id, :string)
end
@required_fields ~w(aggregate_id)a
@impl true
def valid?(command) do
data = Map.from_struct(command)
%__MODULE__{}
|> cast(data, @required_fields)
|> validate_required(@required_fields)
|> Map.get(:valid?)
end
end
Then, let's create an event data structure called Account Opened to hold the data to reference the successful operation. Similar to commands, event data can be implemented using Ecto Schema or Elixir structs.
defmodule Bank.Events.AccountOpened do
use Ecto.Schema
@primary_key false
embedded_schema do
field(:aggregate_id, :string)
field(:account_number, :string)
field(:version, :integer)
end
end
Any operation in our bank application will happen or not based on some logic that we will define. The place for this logic is the Bank Account aggregate module. We also need to create the Bank Account State, that will specify what is the initial state of a bank account:
defmodule Bank.BankAccountState do
use Incident.AggregateState,
aggregate: Bank.BankAccount,
initial_state: %{
aggregate_id: nil,
account_number: nil,
balance: nil,
version: nil,
updated_at: nil
}
end
An Incident aggregate will implement two functions:
execute/1 will receive a command and based on any logic return an event or an error tuple, and;apply/2 that will receive an event and a state, and return a new state;In our opening account logic, we simply check if the account number already exists, if not, an event is returned, otherwise, the error is returned.
defmodule Bank.BankAccount do
@behaviour Incident.Aggregate
alias Bank.BankAccountState
alias Bank.Commands.OpenAccount
alias Bank.Events.AccountOpened
@impl true
def execute(%OpenAccount{aggregate_id: aggregate_id}) do
case BankAccountState.get(aggregate_id) do
%{account_number: nil} = state ->
new_event = %AccountOpened{
aggregate_id: aggregate_id,
account_number: aggregate_id,
version: 1
}
{:ok, new_event, state}
_state ->
{:error, :account_already_opened}
end
end
@impl true
def apply(%{event_type: "AccountOpened"} = event, state) do
%{
state
| aggregate_id: event.aggregate_id,
account_number: event.event_data["account_number"],
balance: 0,
version: event.version,
updated_at: event.event_date
}
end
end
The Event Handler is the connection between the command side and the query side in the domain. Once an event happens on the command side you can decide what to do on the query side, usually, the aggregate projection is updated with the new data so the UI can read it.
An Incident event handler implements listen/2 that pattern matches the event type, in the AccountOpened example we ask the aggregate to return the new state, and based on that we build the data to be projected. Depending on the event type you can perform other side effects and we will see that in the following posts in this series.
defmodule Bank.BankAccountEventHandler do
@behaviour Incident.EventHandler
alias Bank.Projections.BankAccount
alias Bank.BankAccount, as: Aggregate
alias Incident.ProjectionStore
@impl true
def listen(%{event_type: "AccountOpened"} = event, state) do
new_state = Aggregate.apply(event, state)
data = %{
aggregate_id: new_state.aggregate_id,
account_number: new_state.account_number,
balance: new_state.balance,
version: event.version,
event_id: event.event_id,
event_date: event.event_date
}
ProjectionStore.project(BankAccount, data)
end
end
There is only one missing piece, the entry point. The Command Handler is responsible for that, each command handler specifies what aggregate and event handler should be used.
defmodule Bank.BankAccountCommandHandler do
use Incident.CommandHandler,
aggregate: Bank.BankAccount,
event_handler: Bank.BankAccountEventHandler
end
With that in place, you can start issuing commands via Bank.BankAccountCommandHandler.receive/1:
# Create a command to open an account
iex 1 > command_open = %Bank.Commands.OpenAccount{aggregate_id: Ecto.UUID.generate()}
%Bank.Commands.OpenAccount{aggregate_id: "10f60355-9a81-47d0-ab0c-3ebedab0bbf3"}
# Successful command for opening an account
iex 2 > Bank.BankAccountCommandHandler.receive(command_open)
{:ok,
%Incident.EventStore.PostgresEvent{
__meta__: #Ecto.Schema.Metadata<:loaded, "events">,
aggregate_id: "10f60355-9a81-47d0-ab0c-3ebedab0bbf3",
event_data: %{
"account_number" => "10f60355-9a81-47d0-ab0c-3ebedab0bbf3",
"aggregate_id" => "10f60355-9a81-47d0-ab0c-3ebedab0bbf3",
"version" => 1
},
event_date: #DateTime<2020-10-31 23:17:30.074416Z>,
event_id: "072fcfce-9521-4432-a2e0-517659590556",
event_type: "AccountOpened",
id: 5,
inserted_at: #DateTime<2020-10-31 23:17:30.087480Z>,
updated_at: #DateTime<2020-10-31 23:17:30.087480Z>,
version: 1
}}
# Failed command as the account number already exists
iex 3 > Bank.BankAccountCommandHandler.receive(command_open)
{:error, :account_already_open}
# Fetching a specific bank account from the Projection Store based on its aggregate id
iex 4 > Incident.ProjectionStore.get(Bank.Projections.BankAccount, "10f60355-9a81-47d0-ab0c-3ebedab0bbf3")
%Bank.Projections.BankAccount{
__meta__: #Ecto.Schema.Metadata<:loaded, "bank_accounts">,
account_number: "10f60355-9a81-47d0-ab0c-3ebedab0bbf3",
aggregate_id: "10f60355-9a81-47d0-ab0c-3ebedab0bbf3",
balance: 0,
event_date: #DateTime<2020-10-31 23:17:30.074416Z>,
event_id: "072fcfce-9521-4432-a2e0-517659590556",
id: 2,
inserted_at: #DateTime<2020-10-31 23:17:30.153274Z>,
updated_at: #DateTime<2020-10-31 23:17:30.153274Z>,
version: 1
}
# Fetching all events for a specific aggregate id
iex 5 > Incident.EventStore.get("10f60355-9a81-47d0-ab0c-3ebedab0bbf3")
[
%Incident.EventStore.PostgresEvent{
__meta__: #Ecto.Schema.Metadata<:loaded, "events">,
aggregate_id: "10f60355-9a81-47d0-ab0c-3ebedab0bbf3",
event_data: %{
"account_number" => "10f60355-9a81-47d0-ab0c-3ebedab0bbf3",
"aggregate_id" => "10f60355-9a81-47d0-ab0c-3ebedab0bbf3",
"version" => 1
},
event_date: #DateTime<2020-10-31 23:17:30.074416Z>,
event_id: "072fcfce-9521-4432-a2e0-517659590556",
event_type: "AccountOpened",
id: 5,
inserted_at: #DateTime<2020-10-31 23:17:30.087480Z>,
updated_at: #DateTime<2020-10-31 23:17:30.087480Z>,
version: 1
}
]
With Incident you can implement Event Sourcing in specific domains in your application. The library will take care of the foundation pieces internally, guiding you through some of the Event Sourcing aspects and components, but at the same time, giving you total control and flexibility in terms of your application logic and processing. With all of the good things present in Elixir, you can decide, for example, what level of concurrency you want, if you need, but Incident will not force you.
The idea behind Incident is being a framework for the Event Sourcing related things, relying on adopted persistence solutions like Ecto, but allowing your application to leverage what you prefer on anything else.
Lots of the code in this first post of the series were setting up things that are very common in most Elixir applications that use Postgres, and some one-time Incident configuration.
The next posts will cover other use-cases in the bank application and the majority of the code will be logic to declare the next operations, some of them, simple, but others, complex.
Check the Incident Github repo for the complete bank application example, including lots of integration tests. Feel free to share it and contribute, the library is somehow new, and any feedback is welcomed. See you soon!